
|
I am a PhD student at The Hong Kong University of Science and Technology (Guangzhou), exploring the field of robotics and artificial intelligence. Prior to that, I studied Intelligence Science and Technology at Sun Yat-sen University as an undergraduate, and generation-based Natural Language Processing at Harbin Institute of Technology (Shenzhen) as a master’s student. My current research interest is unifying world modeling and policy learning. I wish to create an end-to-end generalist agent in the physical world. |
|
pdf |
abstract |
code
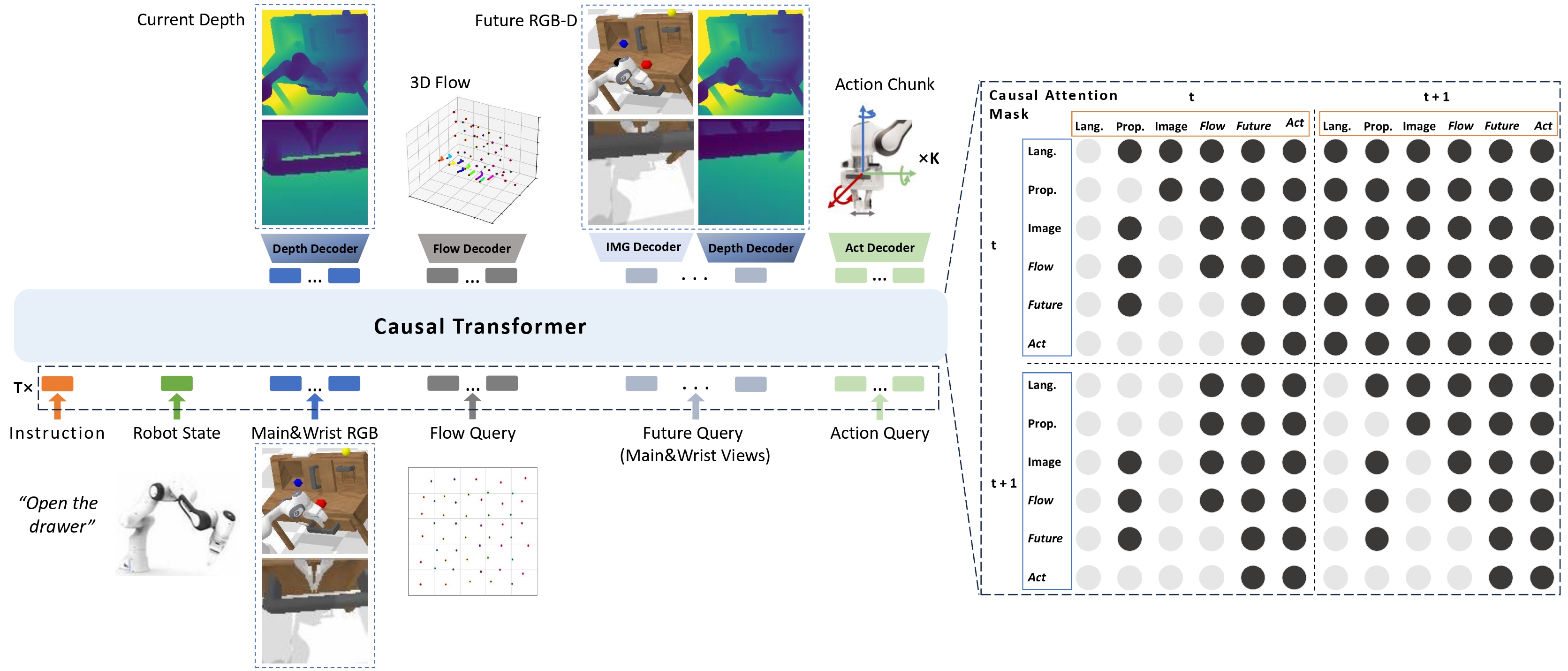
The incorporation of world modeling into manipulation policy learning has pushed the boundary of manipulation performance. However, existing efforts simply model the 2D visual dynamics, which is insufficient for robust manipulation when target tasks involve prominent depth-wise movement. To address this, we present a 3D dynamics-aware manipulation framework that seamlessly integrates 3D world modeling and policy learning. Three self-supervised learning tasks (current depth estimation, future RGB-D prediction, 3D flow prediction) are introduced within our framework, which complement each other and endow the policy model with 3D foresight. Extensive experiments on simulation and the real world show that 3D foresight can greatly boost the performance of manipulation policies without sacrificing inference speed. Code is available at https://github.com/Stardust-hyx/3D-Foresight. |
|
pdf |
abstract |
webpage
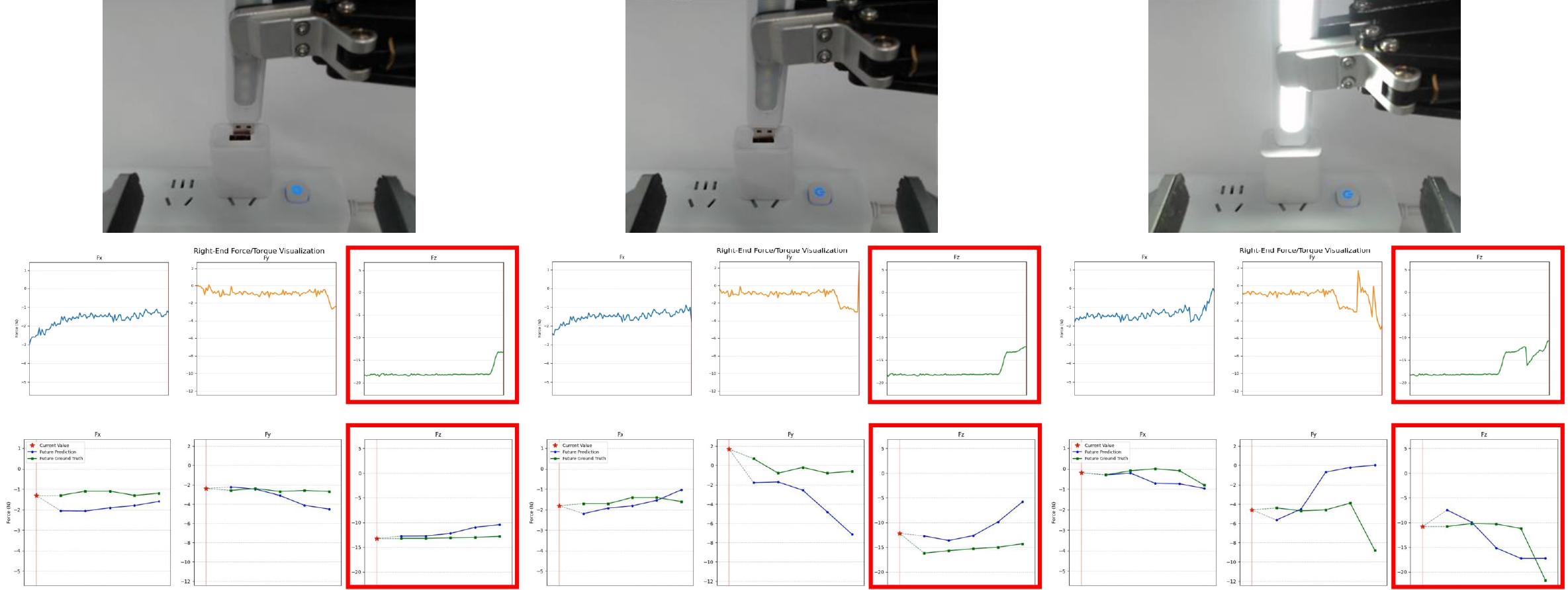
Recently, active vision has reemerged as an important concept for manipulation, since visual occlusion occurs more frequently when main cameras are mounted on the robot heads. We reflect on the visual occlusion issue and identify its essence as the absence of information useful for task completion. Inspired by this, we come up with the more fundamental problem of Exploratory and Focused Manipulation (EFM). The proposed problem is about actively collecting information to complete challenging manipulation tasks that require exploration or focus. As an initial attempt to address this problem, we establish the EFM-10 benchmark that consists of 4 categories of tasks that align with our definition (10 tasks in total). We further come up with a Bimanual Active Perception (BAP) strategy, which leverages one arm to provide active vision and another arm to provide force sensing while manipulating. Based on this idea, we collect a dataset named BAPData for the tasks in EFM-10. With the dataset, we successfully verify the effectiveness of the BAP strategy in an imitation learning manner. We hope that the EFM-10 benchmark along with the BAP strategy can become a cornerstone that facilitates future research towards this direction. Project website: EFManipulation.github.io. |
|
pdf |
abstract |
code
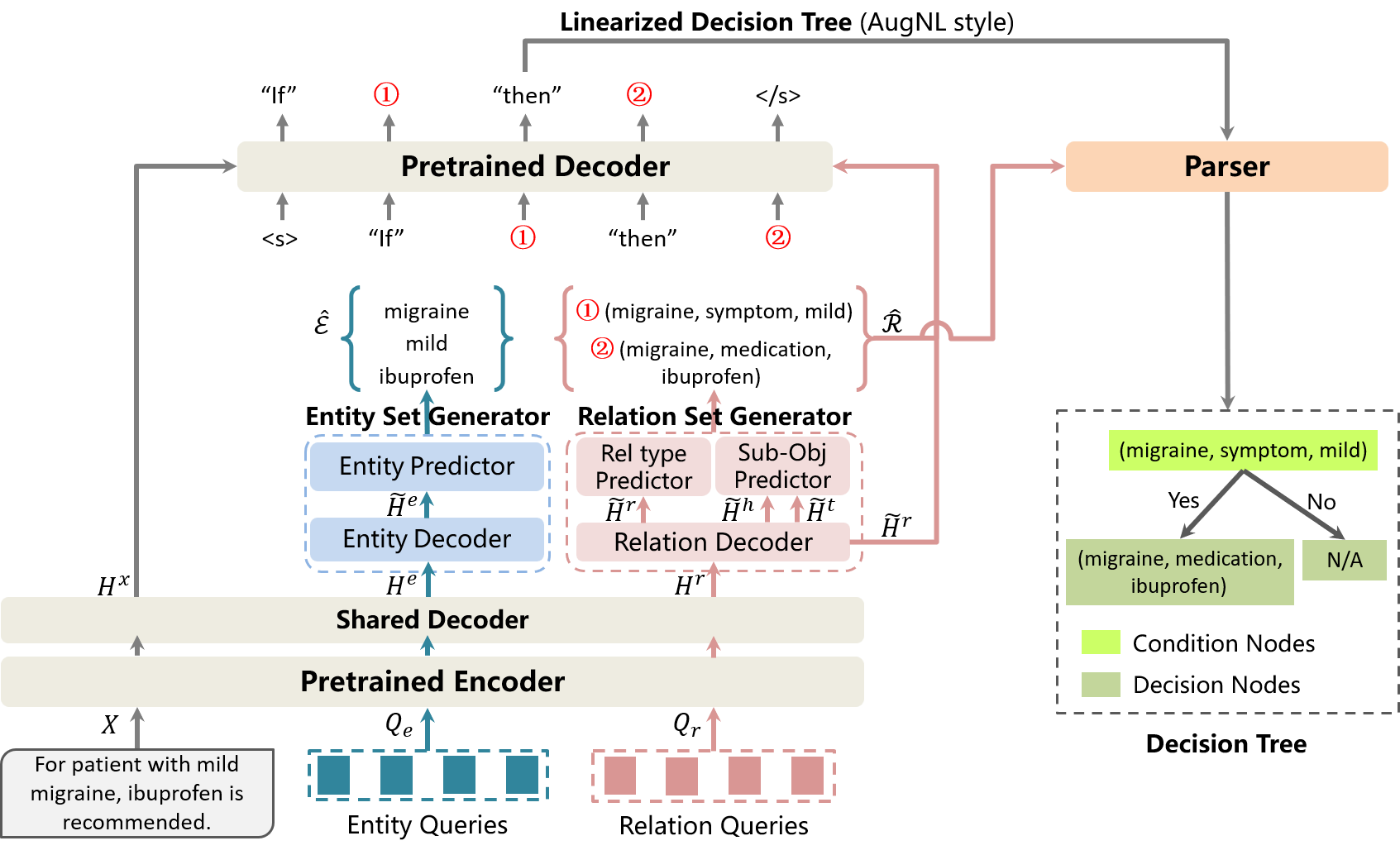
Medical decision rules play a key role in many clinical decision support systems (CDSS). However, these rules are conventionally constructed by medical experts, which is expensive and hard to scale up. In this study, we explore the automatic extraction of medical decision rules from text, leading to a solution to construct large-scale medical decision rules. We adopt a formulation of medical decision rules as binary trees consisting of condition/decision nodes. Such trees are referred to as medical decision trees and we introduce several generative models to extract them from text. The proposed models inherit the merit of two categories of successful natural language generation frameworks, i.e., sequence-to-sequence generation and autoregressive generation. To unleash the potential of pretrained language models, we design three styles of linearization (natural language, augmented natural language and JSON code), acting as the target sequence for our models. Our final system achieves 67% tree accuracy on a comprehensive Chinese benchmark, outperforming state-of-the-art baseline by 12%. The result demonstrates the effectiveness of generative models on explicitly modeling structural decision-making roadmaps, and shows great potential to boost the development of CDSS and explainable AI. Our code is avilable at https://github.com/Stardust-hyx/Generative_Text2DT. |
|
pdf |
abstract |
code
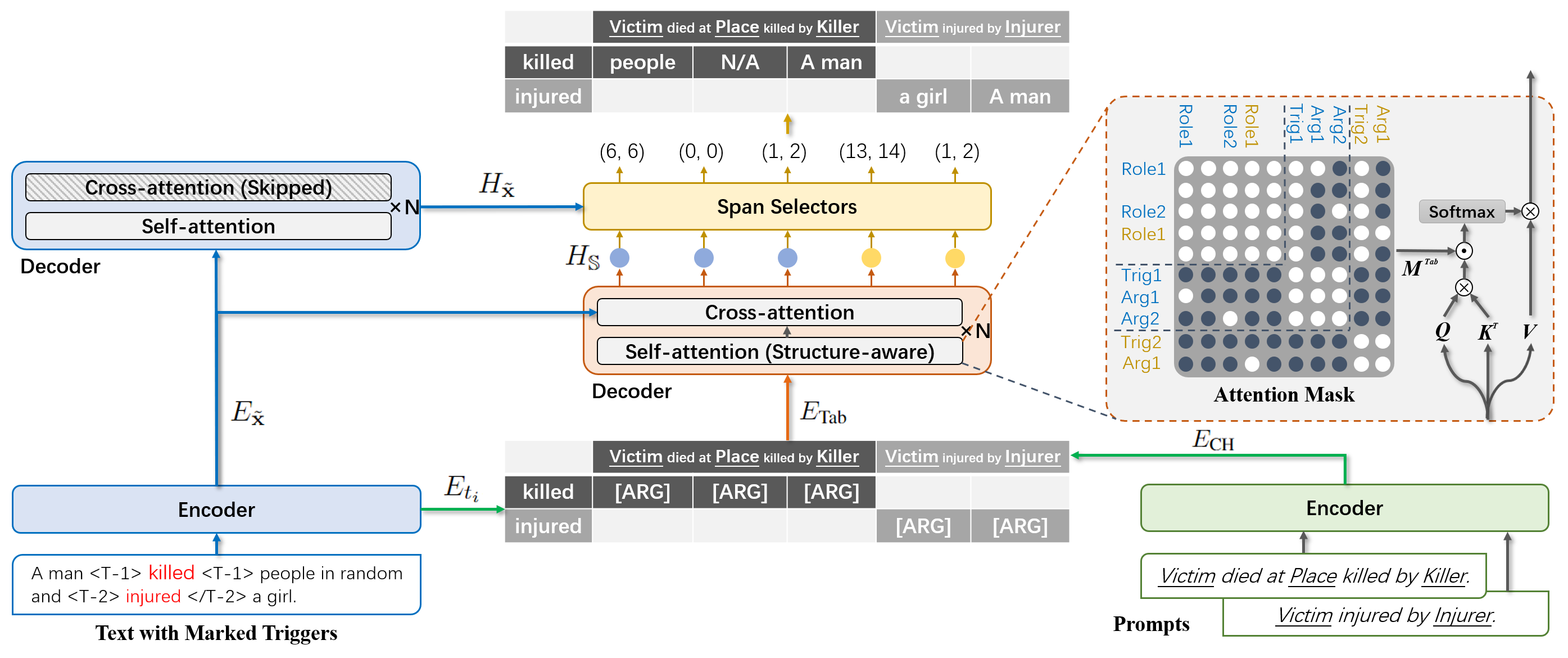
Event co-occurrences have been proved effective for event extraction (EE) in previous studies, but have not been considered for event argument extraction (EAE) recently. In this paper, we try to fill this gap between EE research and EAE research, by highlighting the question that “Can EAE models learn better when being aware of event co-occurrences?”. To answer this question, we reformulate EAE as a problem of table generation and extend a SOTA prompt-based EAE model into a non-autoregressive generation framework, called TabEAE, which is able to extract the arguments of multiple events in parallel. Under this framework, we experiment with 3 different training-inference schemes on 4 datasets (ACE05, RAMS, WikiEvents and MLEE) and discover that via training the model to extract all events in parallel, it can better distinguish the semantic boundary of each event and its ability to extract single event gets substantially improved. Experimental results show that our method achieves new state-of-the-art performance on the 4 datasets. Our code is avilable at https://github.com/Stardust-hyx/TabEAE. |
|
pdf |
abstract |
code
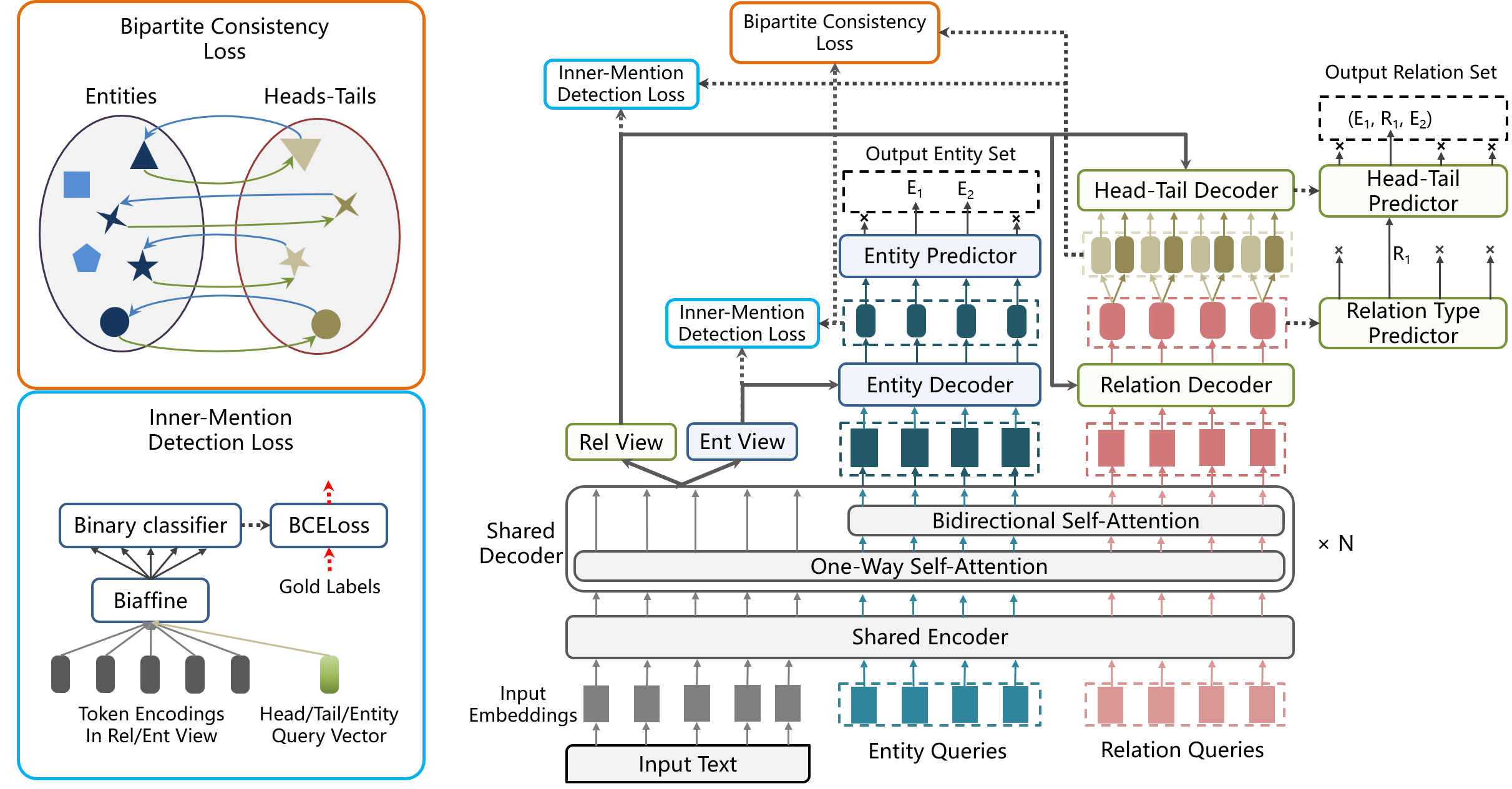
By modeling the interaction among instances and avoiding error propagation, Set Prediction Networks (SPNs) achieve state-of-the-art performance on the tasks of named entity recognition and relation triple extraction respectively. However, how to jointly extract entities and relation triples via SPNs remains an unexplored problem, where the main challenge is the maintenance of coherence between the predicted entity/relation sets during one-pass generation. In this work, we present Bipartite Set Prediction Network (BiSPN), a novel joint entity-relation extraction model that can efficiently generate entity set and relation set in parallel. To overcome the challenge of coherence, BiSPN is equipped with a novel bipartite consistency loss as well as an entity-relation linking loss during training. Experiments on three biomedical/clinical datasets and a general-domain dataset show that BiSPN achieves new state of the art in knowledge-intensive scene and performs competitively in general-domain, while being more efficient than two-stage joint extraction methods. |
|
pdf |
abstract |
code
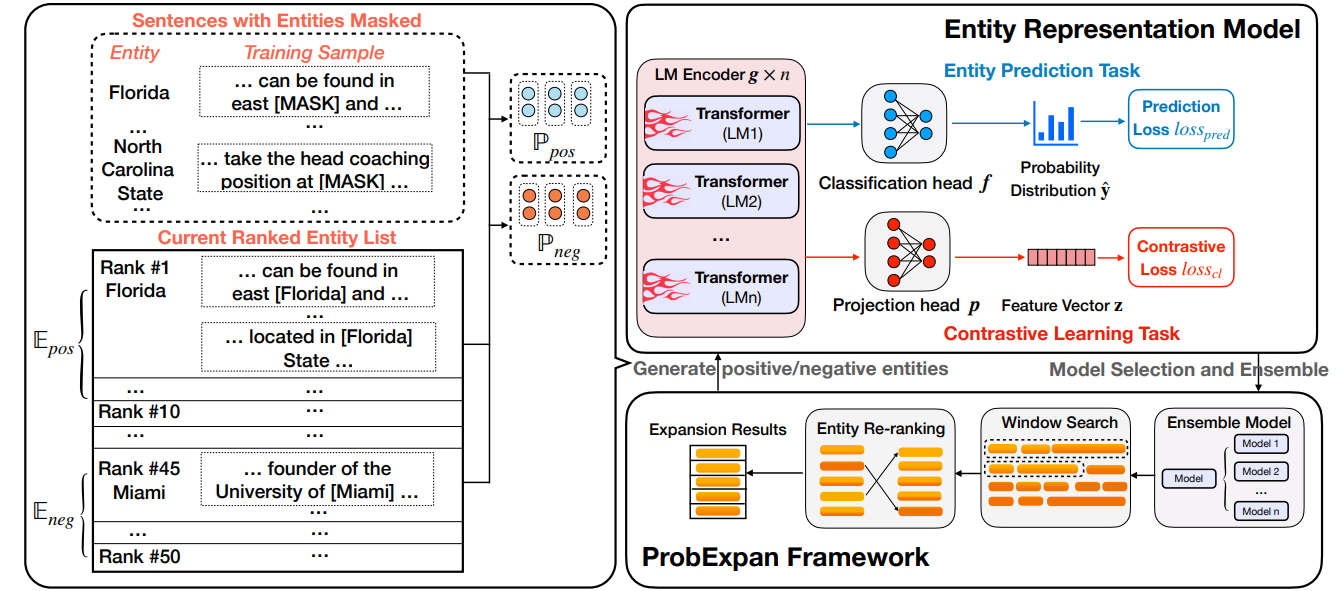
Entity Set Expansion (ESE) is a promising task which aims to expand entities of the target semantic class described by a small seed entity set. Various NLP and IR applications will benefit from ESE due to its ability to discover knowledge. Although previous ESE methods have achieved great progress, most of them still lack the ability to handle hard negative entities (i.e., entities that are difficult to distinguish from the target entities), since two entities may or may not belong to the same semantic class based on different granularity levels we analyze on. To address this challenge, we devise an entity-level masked language model with contrastive learning to refine the representation of entities. In addition, we propose the ProbExpan, a novel probabilistic ESE framework utilizing the entity representation obtained by the aforementioned language model to expand entities. Extensive experiments and detailed analyses on three datasets show that our method outperforms previous state-of-the-art methods. |
|
pdf |
abstract |
code
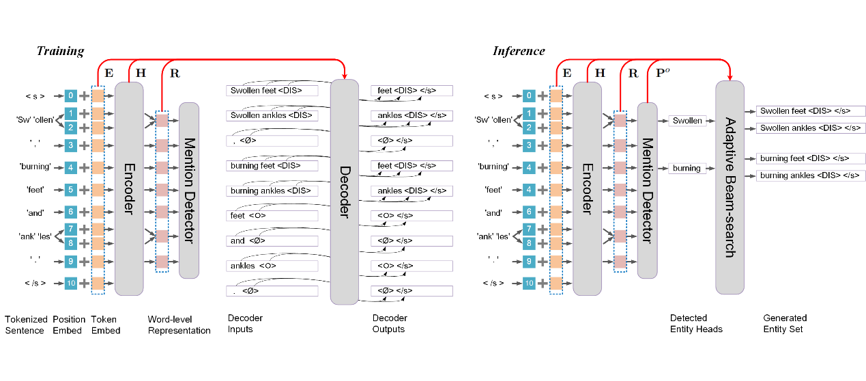
Recently, joint recognition of flat, nested and discontinuous entities has received increasing attention. Motivated by the observation that the target output of NER is essentially a set of sequences, we propose a novel entity set generation framework for general NER scenes in this paper. Different from sequence-to-sequence NER methods, our method does not force the entities to be generated in a predefined order and can get rid of the problem of error propagation and inefficient decoding. Distinguished from the set-prediction NER framework, our method treats each entity as a sequence and is capable of recognizing discontinuous mentions. Given an input sentence, the model first encodes the sentence in word-level and detects potential entity mentions based on the encoder’s output, then reconstructs entity mentions from the detected entity heads in parallel. To let the encoder of our model capture better right-to-left semantic structure, we also propose an auxiliary Inverse Generation Training task. Extensive experiments show that our model (w/o. Inverse Generation Training) outperforms state-of-the-art generative NER models by a large margin on two discontinuous NER datasets, two nested NER datasets and one flat NER dataset. Besides, the auxiliary Inverse Generation Training task is found to further improve the model’s performance on the five datasets. |

|
|

|
|
|
|
|
|
|
|
|
|
Website template from here |